
Microsoft experimentó una interrupción significativa en varios servicios en la nube de Azure el 30 de julio de 2024 debido a un ataque de denegación de servicio distribuido (DDoS). El ataque, dirigido a los servicios Azure y Microsoft 365, se vio exacerbado por un error en los mecanismos de defensa DDoS de Microsoft, lo que provocó una interrupción que duró casi ocho horas.
Microsoft experimentó una interrupción significativa en varios servicios en la nube de Azure el 30 de julio de 2024 debido a un ataque de denegación de servicio distribuido (DDoS). El ataque, dirigido a los servicios Azure y Microsoft 365, se vio exacerbado por un error en los mecanismos de defensa DDoS de Microsoft, lo que provocó una interrupción que duró casi ocho horas.
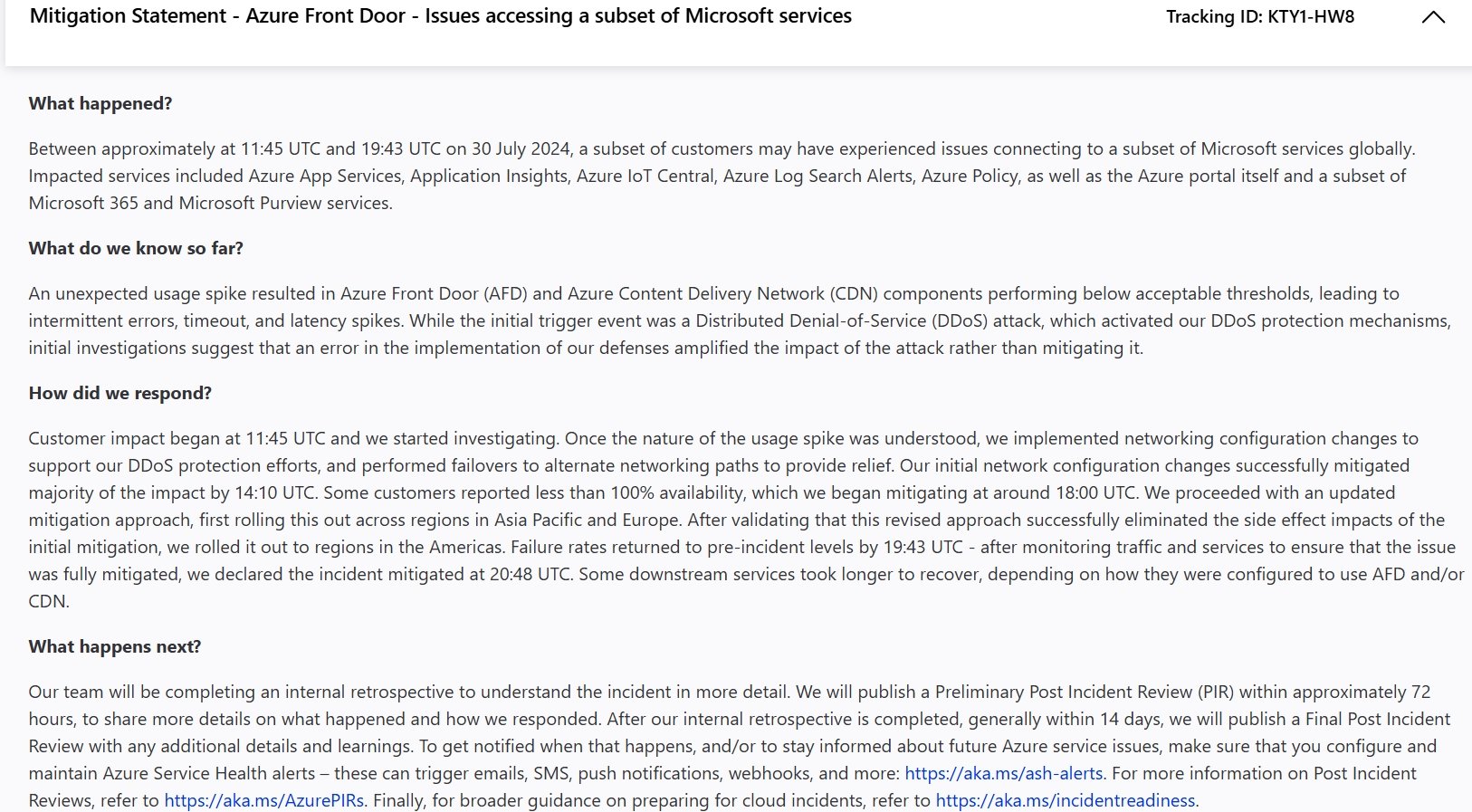
Resumen del incidente
Aproximadamente entre las 11:45 UTC y las 19:43 UTC, un subconjunto de clientes de Microsoft en todo el mundo enfrentaron problemas para conectarse a varios servicios. Los servicios afectados incluyeron Azure App Services, Application Insights, Azure IoT Central, Azure Log Search Alerts, Azure Policy, Azure Portal y un subconjunto de servicios de Microsoft 365 y Microsoft Purview.
Análisis de raíz de la causa
Un aumento inesperado en el uso provocó que los componentes de Azure Front Door (AFD) y Azure Content Delivery Network (CDN) tuvieran un rendimiento inferior, lo que provocó errores intermitentes, tiempos de espera y picos de latencia. El desencadenante inicial fue un ataque DDoS, que activó los mecanismos de protección DDoS de Microsoft. Sin embargo, las investigaciones sugieren que un error en la implementación de estas defensas amplificó el impacto del ataque en lugar de mitigarlo.
La respuesta de Microsoft
El impacto en el cliente comenzó a las 11:45 UTC, lo que provocó una investigación inmediata. Al comprender la naturaleza del aumento de uso, Microsoft implementó cambios en la configuración de red para respaldar los esfuerzos de protección DDoS y realizó conmutaciones por error para alternativas de rutas de red para aliviarlo.
A las 14:10 UTC, los cambios iniciales en la configuración de la red habían mitigado la mayor parte del impacto. No obstante, algunos clientes continuaron informando menos del 100% de disponibilidad. Microsoft abordó este problema alrededor de las 18:00 UTC implementando un enfoque de mitigación actualizado primero en Asia Pacífico y Europa. Luego de validar su efectividad, lo extendieron a América. Las tasas de fallas volvieron a los niveles anteriores al incidente a las 19:43 UTC y el incidente se declaró mitigado a las 20:48 UTC. Algunos servicios posteriores tardaron más en recuperarse, dependiendo de sus configuraciones de AFD y/o CDN.
Acciones futuras
El equipo de Microsoft completará una retrospectiva interna para comprender el incidente con más detalle. Planean publicar una revisión preliminar posterior al incidente (PIR) dentro de aproximadamente 72 horas, brindando más detalles sobre el incidente y la respuesta. Se realizará una revisión final posterior al incidente, con detalles y aprendizajes adicionales, dentro de los 14 días. Para mantenerse informados sobre futuros problemas del servicio Azure, se recomienda a los clientes configurar alertas de Azure Service Health, que pueden activar notificaciones por correo electrónico, SMS, notificaciones push, webhooks y más.
Resumen del incidente
Aproximadamente entre las 11:45 UTC y las 19:43 UTC, un subconjunto de clientes de Microsoft en todo el mundo enfrentaron problemas para conectarse a varios servicios. Los servicios afectados incluyeron Azure App Services, Application Insights, Azure IoT Central, Azure Log Search Alerts, Azure Policy, Azure Portal y un subconjunto de servicios de Microsoft 365 y Microsoft Purview.
Análisis de raíz de la causa
Un aumento inesperado en el uso provocó que los componentes de Azure Front Door (AFD) y Azure Content Delivery Network (CDN) tuvieran un rendimiento inferior, lo que provocó errores intermitentes, tiempos de espera y picos de latencia. El desencadenante inicial fue un ataque DDoS, que activó los mecanismos de protección DDoS de Microsoft. Sin embargo, las investigaciones sugieren que un error en la implementación de estas defensas amplificó el impacto del ataque en lugar de mitigarlo.
La respuesta de Microsoft
El impacto en el cliente comenzó a las 11:45 UTC, lo que provocó una investigación inmediata. Al comprender la naturaleza del aumento de uso, Microsoft implementó cambios en la configuración de red para respaldar los esfuerzos de protección DDoS y realizó conmutaciones por error para alternativas de rutas de red para aliviarlo.
A las 14:10 UTC, los cambios iniciales en la configuración de la red habían mitigado la mayor parte del impacto. No obstante, algunos clientes continuaron informando menos del 100% de disponibilidad. Microsoft abordó este problema alrededor de las 18:00 UTC implementando un enfoque de mitigación actualizado primero en Asia Pacífico y Europa. Luego de validar su efectividad, lo extendieron a América. Las tasas de fallas volvieron a los niveles anteriores al incidente a las 19:43 UTC y el incidente se declaró mitigado a las 20:48 UTC. Algunos servicios posteriores tardaron más en recuperarse, dependiendo de sus configuraciones de AFD y/o CDN.
Acciones futuras
El equipo de Microsoft completará una retrospectiva interna para comprender el incidente con más detalle. Planean publicar una revisión preliminar posterior al incidente (PIR) dentro de aproximadamente 72 horas, brindando más detalles sobre el incidente y la respuesta. Se realizará una revisión final posterior al incidente, con detalles y aprendizajes adicionales, dentro de los 14 días. Para mantenerse informados sobre futuros problemas del servicio Azure, se recomienda a los clientes configurar alertas de Azure Service Health, que pueden activar notificaciones por correo electrónico, SMS, notificaciones push, webhooks y más.
Es un conocido experto en seguridad móvil y análisis de malware. Estudió Ciencias de la Computación en la NYU y comenzó a trabajar como analista de seguridad cibernética en 2003. Trabaja activamente como experto en antimalware. También trabajó para empresas de seguridad como Kaspersky Lab. Su trabajo diario incluye investigar sobre nuevos incidentes de malware y ciberseguridad. También tiene un profundo nivel de conocimiento en seguridad móvil y vulnerabilidades móviles.